Robots.txt 란?
지난 글에서는 블로그 운영, 웹사이트 운영을 위한 2가지 작업을 다루었습니다.
1. 네이버 웹마스터 도구/구글 서치콘솔 HTML 태그등록
(내용이 생소하다면, 먼저 읽어보시길 바랍니다.)
자, 이제 검색 엔진에게 나의 블로그가 어떻게 생겨먹었는지
친절하게 알려주었습니다.
그러면 검색 엔진은 로봇을 통해
블로그에 존재하는 콘텐츠들을 수집합니다.
이를 통해 검색 결과로 블로그 글이 노출되는 것이죠.
그럼 Robots.txt 는 무엇일까요?
'Robots.txt' 는 로봇 배제 표준에 대한 웹사이트 지침입니다.
(로봇 배제 표준은 웹사이트에 로봇의 접근을 방지하기 위한 규약 - 위키피디아 로봇 배제 표준)
쉽게 설명하면
검색엔진의 로봇은 정해진 규칙에 따라 움직입니다.
이러한 규칙을 결정하는 설명서가 robots.txt인 셈입니다.
그래서 오늘은 검색 로봇이 블로그에서
어떻게 콘텐츠를 수집할지를 결정하는 규칙 작성을 진행합니다.
(티스토리에서는 자체적으로 robots.txt를 제공해주고 있기는 합니다.)
이를 통해 자신이 원하지 않는 페이지 혹은 콘텐츠를
검색 로봇이 수집하지 않도록 설정할 수도 있습니다!

1. 간단하게 Robots.txt 만들기
우선 먼저 밝혀드리는 점은,
티스토리 블로그 사용자는 Robots.txt 를 생성할 필요가 없습니다.
티스토리에서 자체적으로 제공하며,
사용자가 블로그 비공개를 목적으로 할 때에만 변경이 가능합니다.
그러므로 해당 글은 다른 블로그 서비스를 이용하는 사용자에게 해당합니다.
검색 로봇에게 알려줄 설명서를 만드는 작업은 그렇게 어렵지 않습니다.
다행히 네이버에서 가장 쉬운 방법을 제공해주고 있기 때문에
이를 활용하여 간단하게 작성하도록 하겠습니다.
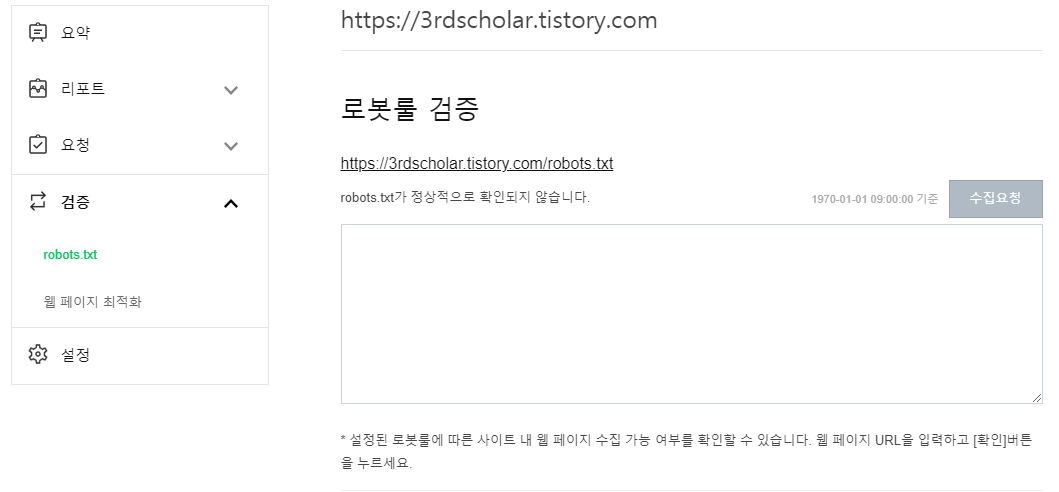
위의 이미지처럼 현재 제 블로그 역시 로봇룰이 확인되지 않습니다.
네이버 웹마스터도구에 접속하여 검증 > robots.txt 를 클릭하면,
아래에 다음과 같은 이미지를 확인할 수 있습니다.
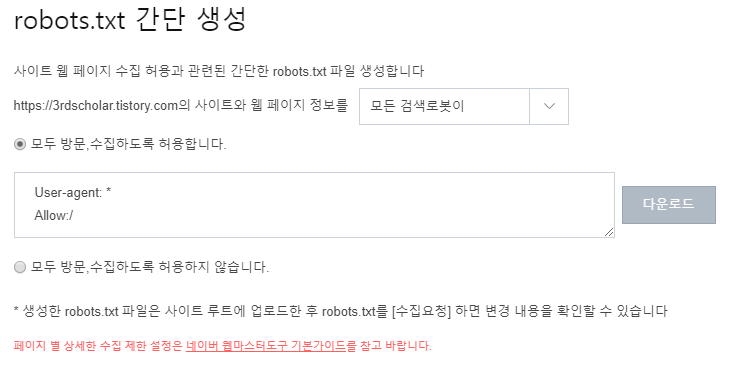
가능한 많은 곳에서 블로그 콘텐츠를 노출시키기 위하여,
위의 사진 처럼 '모든 검색로봇이' 방문, 수집할 수 있도록 허용합니다.
다운로드를 해주면 robots.txt 만드는 작업은 끝나게 됩니다.
이후에는 호스팅 서버나 루트 디렉토리에
robots.txt 파일을 업로드하면 마무리됩니다.
2. robots.txt 문법
Robots.txt 구조
- User-agent → 어떤 검색 로봇을 지칭하는가?
- Allow → 어떤 링크를 허용하는가?
- Disallow → 어떤 링크를 허용하지 않는가?
이렇게 보면 생각보다 단순하게 느껴지실 겁니다.
예시를 들어 확인하겠습니다.
1) 네이버 간단 생성 robots.txt: 모든 검색 로봇이 모두 방문, 수집하도록 허용합니다.
User-agent: *
Allow:/모든 검색 로봇이라는 의미를 * 문자를 통해 나타냅니다.
해당 웹사이트의 모든 URL을 / 문자를 통해 나타냅니다.
2) 네이버 간단 생성 robots.txt: 네이버 검색 로봇이 모두 방문, 수집하도록 허용하지 않습니다.
User-agent: Yeti
Disallow:/네이버 검색 로봇이라는 의미를 Yeti 로 나타냅니다.
해당 웹사이트의 모든 URL을 / 문자를 통해 나타냅니다.
자, 이제 실전입니다!
티스토리 robots.txt 에 대해 알아보겠습니다.
3) 티스토리 robots.txt
User-agent: *
Disallow: /owner
Disallow: /manage
Disallow: /admin
Disallow: /oldadmin
Disallow: /search
Disallow: /m/search
Disallow: /m/admin
Disallow: /like
Allow: /
User-agent: Mediapartners-Google
Allow: /
User-agent: bingbot
Crawl-delay: 30
윗 부분부터 살펴보겠습니다.
모든 검색 로봇(User-agent: *)이 모든 URL 방문, 수집하는 것을 허용합니다. (Allow:/)
다만, /owner, /manage, /admin, /oladmin, /search, /m/search, /m/admin, /like 페이지는
모든 검색 로봇이 방문, 수집하는 것을 허용하지 않습니다. (Disallow: )
다음 부분을 살펴보겠습니다.
Mediapartners-Google 검색 로봇이 모든 URL 방문, 수집하는 것을 허용합니다.
마지막 부분입니다.
bingbot (Bing의 검색 로봇)은 크롤링을 30초의 딜레이를 가지게 합니다.
즉, 30초의 지연 시간을 둡니다.
(얼마나 격렬하게 검색 로봇들이 달려들길래, 30초의 딜레이를 두는 것인지 궁금할 정도네요.)
참고로 각 검색 엔진의 크롤링 봇들의 별칭을 정리하고 넘어가겠습니다.
- 네이버: Yeti, naverbot
- 구글: Googlebot
- 야후: Slurp, yahoo-slurp
- 다음: Daumos
- 빙: Bingbot
- MSN: MSNBot
이외에도 찾아보시면, 다양한 검색 로봇이 있음을 확인하실 수 있을 겁니다.
3. 티스토리 블로그는 자체적으로 제공되는 robots. txt 가 있습니다.
이번 글에서 티스토리와 관련하여
많은 블로그들이 잘못 알려주는 부분이 있어 이를 정정하고자 합니다.
관리자 페이지의 스킨 편집 기능을 통해,
robots.txt 파일을 업로드하는 방법에 대한 글이 정말 많습니다.
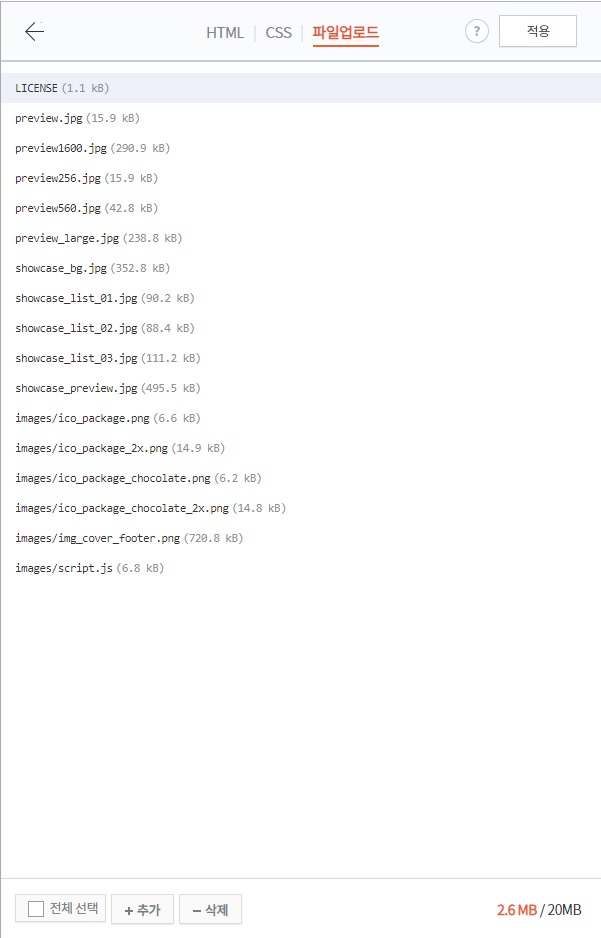
왼쪽 이미지의 파일 업로드 기능을 사용하더라도
해당 블로그의 robots.txt는 변하지 않습니다.
제대로 robots.txt 가 업로드 되고 적용되었다면,
아래와 같이 나와야 합니다.
User-agent: *
Allow:/
하지만 '3rdscholar.tistory.com/robots.txt'를
주소창에 입력해 보세요. 제 블로그 것이며,
다음과 같이 나타납니다.
User-agent: *
Disallow: /owner
Disallow: /manage
Disallow: /admin
Disallow: /oldadmin
Disallow: /search
Disallow: /m/search
Disallow: /m/admin
Disallow: /like
Allow: /
User-agent: Mediapartners-Google
Allow: /
User-agent: bingbot
Crawl-delay: 30
즉, 전혀 다른 로봇룰이 적용된 모습이죠.
많은 분들이 무분별하게 robots.txt에 대한 글을 적으면서,
확인이 이루어지지 않은 까닭인 듯 합니다.
부디 티스토리 블로그를 시작하시는 분이라면,
Robots.txt 에 대해 이해하되, 불필요한 시간을 낭비하지 마시길 바랍니다.
대신 구글 서치콘솔의 URL 검사, 또는 네이버 웹마스터도구의 로봇룰 수집요청을 통해
쉽게 해결하고 다음 단계로 나아가시기 바랍니다.
마치며..
이제 블로그를 시작하면서 세팅해야 할 작업들이
대부분 끝이 나고 있습니다.
저 역시, 미약하지만 그 변화를 느끼고 있습니다.
아래 이미지는 해당 블로그의 구글 서치콘솔 결과입니다.

나머지 작업인 RSS 등록,
조금은 사람들이 많이 사용하지 않는 검색 엔진에
각각 내 블로그를 알리는 작업은
이어지는 글에서 다루도록 하겠습니다.
'블로그 운영 관련 정보 > 블로그 노출' 카테고리의 다른 글
| (티스토리) 사이트맵(sitemap.xml) 만들 필요가 없다! (0) | 2020.05.06 |
|---|---|
| 티스토리 블로그 줌(zum), 빙(Bing) 웹마스터 도구에 등록하기 (0) | 2019.11.23 |
| 티스토리는 RSS 설정이 필요하지 않습니다. (Feat. RSS에 대해 이해하기) (1) | 2019.11.20 |
| 검색 노출이 잘 되도록, 네이버 웹마스터도구, 구글 서치콘솔 HTML 태그 등록방법 (0) | 2019.11.12 |



