본 문서의 내용은 한국데이터산업진흥원에서 펴낸 SQL 전문가 가이드를 기반으로 자격증 취득에 도움이 될 개념을 정리한 것입니다.
 |
|
3. 반정규화와 성능
1. 반정규화를 통한 성능향상 전략
가. 반정규화의 정의
반정규화를 정의하면 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발(Development)과 운영(Maintenance)의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링의 기법을 의미한다. 협의의 반정규화는 데이터를 중복하여 성능을 향상시키기 위한 기법이라고 정의할 수 있고 좀 더 넓은 의미의 반정규화는 성능을 향상시키기 위해 정규화된 데이터 모델에서 중복, 통합, 분리 등을 수행하는 모든 과정을 의미한다.
데이터를 조회할 때 디스크 I/O 량이 많아서 성능이 저하되거나 경로가 너무 멀어 조인으로 인한 성능 저하가 예상되거나 칼럼을 계산하여 읽을 때 성능이 저하될 것이 예상되는 경우 반정규화를 수행하게 된다.
반정규화를 수행하지 않았을 경우 발생하는 현상
- 성능이 저하된 데이터베이스가 생성될 수 있다.
- 구축단계나 시험단계에서 반정규화를 적용할 때 수정에 따른 노력비용이 많이 들게 된다.
나. 반정규화의 적용방법
보통 프로젝트에서는 칼럼 중복을 통해서만 반정규화를 수행하게 된다. 칼럼의 반정규화가 많은 이유는 개발을 하다가 SQL 문장 작성이 복잡해지고 그에 따라 SQL 단위 성능 저하가 예상이 되어 다른 테이블에서 조인하여 가져와야 할 칼럼을 기준이 되는 테이블에 중복하여 SQL 문장을 단순하게 처리하도록 하기 위해 요청하는 경우가 많다.

-
반정규화의 대상을 조사한다.
- 자주 사용하는 테이블에 접근(Access)하는 프로세스의 수가 많고 항상 일정 범위만을 조회하는 경우에 반정규화 검토
- 테이블에 대량의 데이터가 있고 대량의 데이터 범위를 자주 처리하는 경우에 처리 범위를 일정하게 줄이지 않으면 성능을 보장할 수 없는 경우
- 통계 정보를 필요로 할 때 별도의 통계 테이블을 생성한다.
- 지나치게 많은 조인이 걸려 데이터 조회 작업이 기술적으로 어려울 경우 반정규화 검토
-
다른 방법으로 처리할 수 있는지 검토한다.
- 성능을 고려한 뷰를 생성하여 개발자가 뷰를 통해 접근하게 함으로써 성능저하의 위험을 예방하는 것도 좋은 방법이 된다.
- 대량의 데이터처리나 부분처리에 의해 성능이 저하되는 경우에 클러스터링을 적용하거나 인덱스를 조정함으로써 성능을 향상시킬 수 있다. 클러스터링을 적용하는 방법은 대량의 데이터를 특정 클러스터링 팩트에 의해 저장방식을 다르게 하는 방법이다. 이 방법의 경우 데이터를 입력/수정/삭제하는 경우 성능이 많이 저하되므로 조회중심의 테이블이 아니라면 생성하면 안되는 오브젝트이다. 다만, 조회가 대부분이고 인덱스를 통해 성능향상이 불가능하다면 클러스터링을 고려할 만하다.
- 인위적인 테이블을 통합/분리하지 않고 물리적인 저장기법에 따라 성능을 향상시킬 수 있는 파티셔닝을 고려해 볼 수 있다. 이 경우는 데이터가 특정 기준(파티셔닝 키)에 의해 다르게 저장되고 파티셔닝 키에 따른 조회가 될 때 성능이 좋아지는 특성이 있다.
- 응용 애플리케이션에서 로직을 구사하는 방법을 변경함으로써 성능을 향상시킬 수 있다. 응용 메모리 영역에 데이터를 처리하기 위한 값을 캐쉬한다든지 중간 클래스 영역에 데이터를 캐쉬하여 공유하게 하여 성능을 향상 시키는 것도 성능을 향상시키는 방법이 될 수 있다.
-
반정규화를 적용한다.
- 테이블, 속성, 관계에 대해 반정규화를 적용할 수 있다.
2. 반정규화의 기법
가. 테이블 반정규화
- 테이블 병합
- 1:1 관계 테이블 병합
- 1:M 관계 테이블 병합
- 슈퍼/서브타입 테이블 병합
- 테이블 분할
- 수직 분할: 컬럼 단위의 테이블을 1:1로 분리
- 수평 분할: 로우 단위로 테이블 분리
- 테이블 추가
- 중복 테이블 추가
- 통계 테이블 추가
- 이력 테이블 추가
- 부분 테이블 추가
나. 컬럼 반정규화
- 중복 컬럼 추가: 조인 감소 목적
- 파생 컬럼 추가: 미리 값을 계산하여 보관 (Derived column)
- 이력 테이블 컬럼 추가: 기능성 컬럼(최근값 여부, 일자 등)을 추가
- PK에 의한 컬럼 추가: PK 안에 데이터가 존재하지만 성능 향상을 위해 일반 속성으로 포함
- 응용시스템 오작동을 위한 컬럼 추가: 이전 데이터를 임시 보관하는 기법
다. 관계 반정규화
- 중복 관계 추가: 추가적인 관계를 맺는 방법
3. 정규화가 잘 정의된 데이터 모델에서 성능이 저하될 수 있는 경우
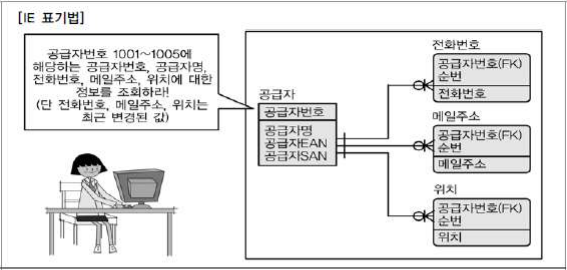
가장 최근에 변경된 값을 마스터 엔터티에 위치시키면 SQL 구문 작성이 간단해진다.

서버 A에 있는 부서명을 서버 B의 연계 테이블에 속성 반정규화를 함으로써 조회 성능을 향상시킬 수 있다.
↓SQL 전문가 가이드 요약 목록
1장. 데이터 모델링의 이해
Part 1. 데이터 모델링의 이해
Part 2. 데이터 모델과 성능
2장. SQL 기본 및 활용
Part 1. SQL 기본
Part 2. SQL 활용
Part 3. SQL 최적화 기본원리
따로 PDF 파일이 필요하신 분은 댓글을 통해 메일 주소 적어주시기 바랍니다.
'데이터 사이언스 > SQL' 카테고리의 다른 글
| [SQLD 학습 자료 요약] 데이터 모델링의 이해 2.5. 데이터베이스 구조와 성능 (0) | 2020.11.17 |
|---|---|
| [SQLD 학습 자료 요약] 데이터 모델링의 이해 2.4. 대량 데이터에 따른 성능 (0) | 2020.11.17 |
| [SQLD 학습 자료 요약] 데이터 모델링의 이해 2.2. 정규화와 성능 (0) | 2020.11.16 |
| [SQLD 학습 자료 요약] 데이터 모델링의 이해 2.1. 성능 데이터 모델링 개요 (1) | 2020.11.16 |
| [SQLD 학습 자료 요약] 데이터 모델링의 이해 1.5. 식별자 (0) | 2020.11.16 |



